Google Made Long Context 5x Cheaper
Table of Contents
Google released a paper that compresses the KV cache - a major bottleneck in LLM inference - by 4.5-5x, depending on how much quality hit you’re willing to take.
At 3.5 bits per channel, benchmarks are identical to full 16-bit precision - including needle-in-a-haystack recall. At 2.5 bits there’s measurable but small degradation.
In practical terms, this means ~5x more context in the same memory budget. Models that currently top out at 32k tokens on your hardware could potentially handle 128k+.
Frameworks like llama.cpp already quantize KV caches, but that leads to significant quality reduction, especially at 4 bits and below. TurboQuant gets better results at fewer bits.
Interestingly, this paper was released sometime in early 2025 and only now has the significance become apparent.
This is probably going to trickle down into open-source tools. I suspect most frontier labs already know about this, but it’s very interesting nonetheless. I’m excited to see how this pushes things forward for open source especially.
How it works
It’s a two-step process.
Step 1: Random rotation
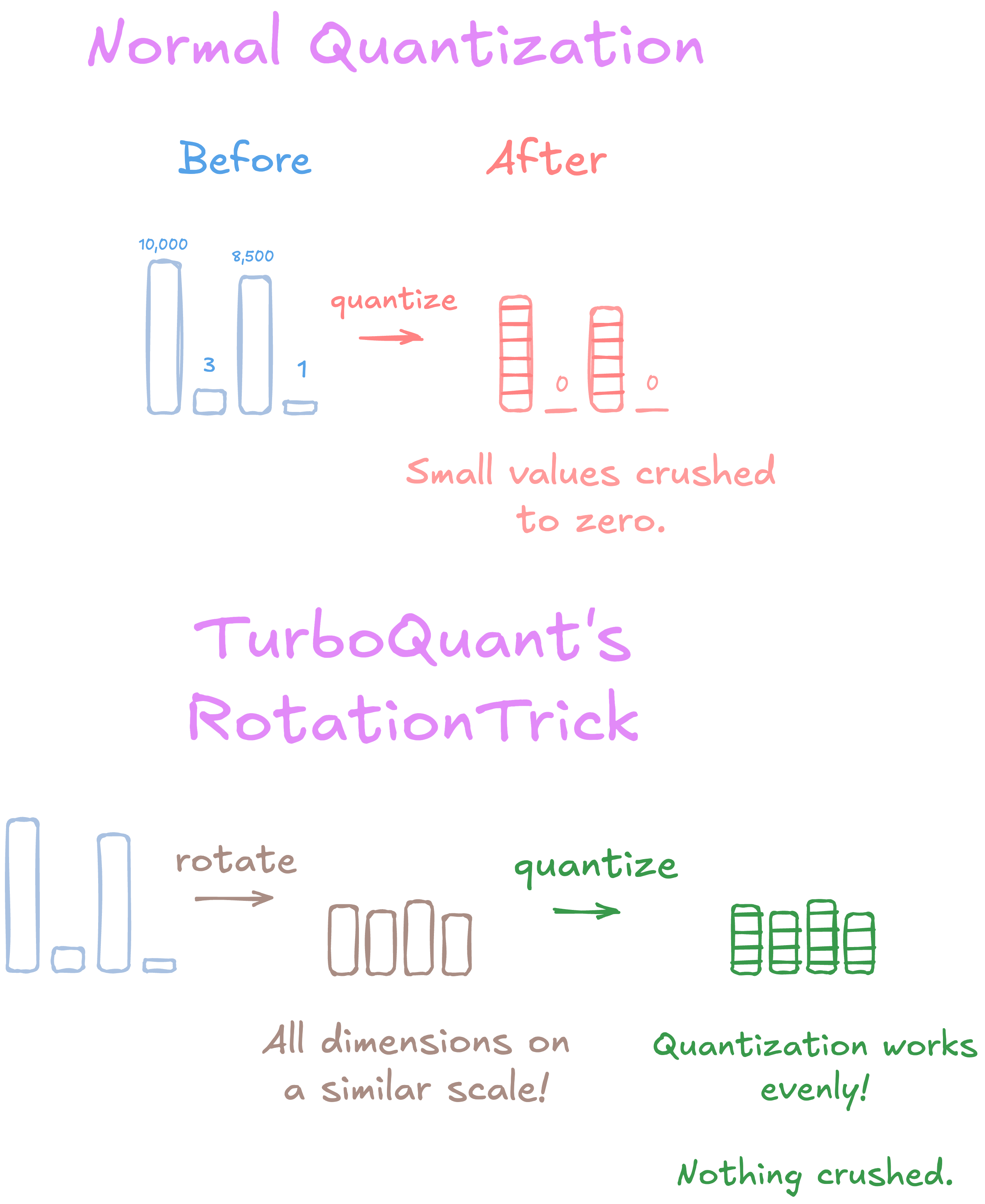
They apply a random rotation to each KV vector before quantizing it. This rotation is proven to make each coordinate follow a known statistical distribution which we know how to quantize with minimal quality loss.
The problem with normal quantization is that different dimensions of a KV vector can have wildly different scales. One dimension might be 10,000, another might be 3. Quantizing them at the same granularity crushes the small values. The rotation evens this out. Every dimension ends up on a similar scale, so quantization works well across all of them.
The rotation matrix is generated deterministically from a seed, shared across all heads and layers. Only the seed needs to be stored. Negligible overhead.
Step 2: Residual quantization
Even after rotation, quantization introduces bias in how inner products are estimated - and inner products are what attention computation depends on. TurboQuant applies a 1-bit correction (a Quantized Johnson-Lindenstrauss transform) on the residual to produce an unbiased estimator. This is what gets them from “pretty good” to “identical to full precision.”
I suspect open-source tools will see big improvements just by implementing the first step alone. The rotation is where most of the gains come from. The second step is a refinement on top.
Paper
TurboQuant: Online Vector Quantization for Efficient KV Cache Compression
This is a simplification of the paper for accessibility. Read the full paper for the precise claims, methodology, and caveats.